Introduction
In the rapidly evolving world of AI and large language models (LLMs), one of the toughest technical problems is integration: connecting a model to real-world data sources (files, databases, APIs), tools (search, scheduling, business logic) and workflows in a secure, maintainable way. Without standardization, every new model + data source becomes a custom integration, leading to a “N×M” explosion of connectors.
The Model Context Protocol (MCP) tackles this by providing a standard protocol and architecture for how AI applications (clients) and external systems (servers) talk to each other. It’s been described as the “USB-C for AI” — one plug, many devices.
Let’s dive into what MCP is, how it works (architecture + lifecycle), what primitives it provides, and how you should think about implementing it.
What is MCP and Why it matters
At its core, MCP is an open standard that defines how an AI client (often wrapping an LLM) can discover, access and execute tools, fetch resources, use prompts, and coordinate with external systems in a standardized way.
Why it matters
- Reduced complexity: Instead of building bespoke connectors for each model and each data source, you build once to the MCP spec and reuse.
- Interoperability: Models, clients, servers from different vendors can align if they all speak MCP.
- Cleaner architecture for agents & tools: Provides a clear boundary between the AI “brain” and the external “body” / world.
- Security & governance: By formalizing tool listings, resource access, prompts and capabilities, MCP enables clearer auditing, user permissioning and regulation.
Architecture Overview
MCP’s architecture is relatively simple conceptually but rich in implications.
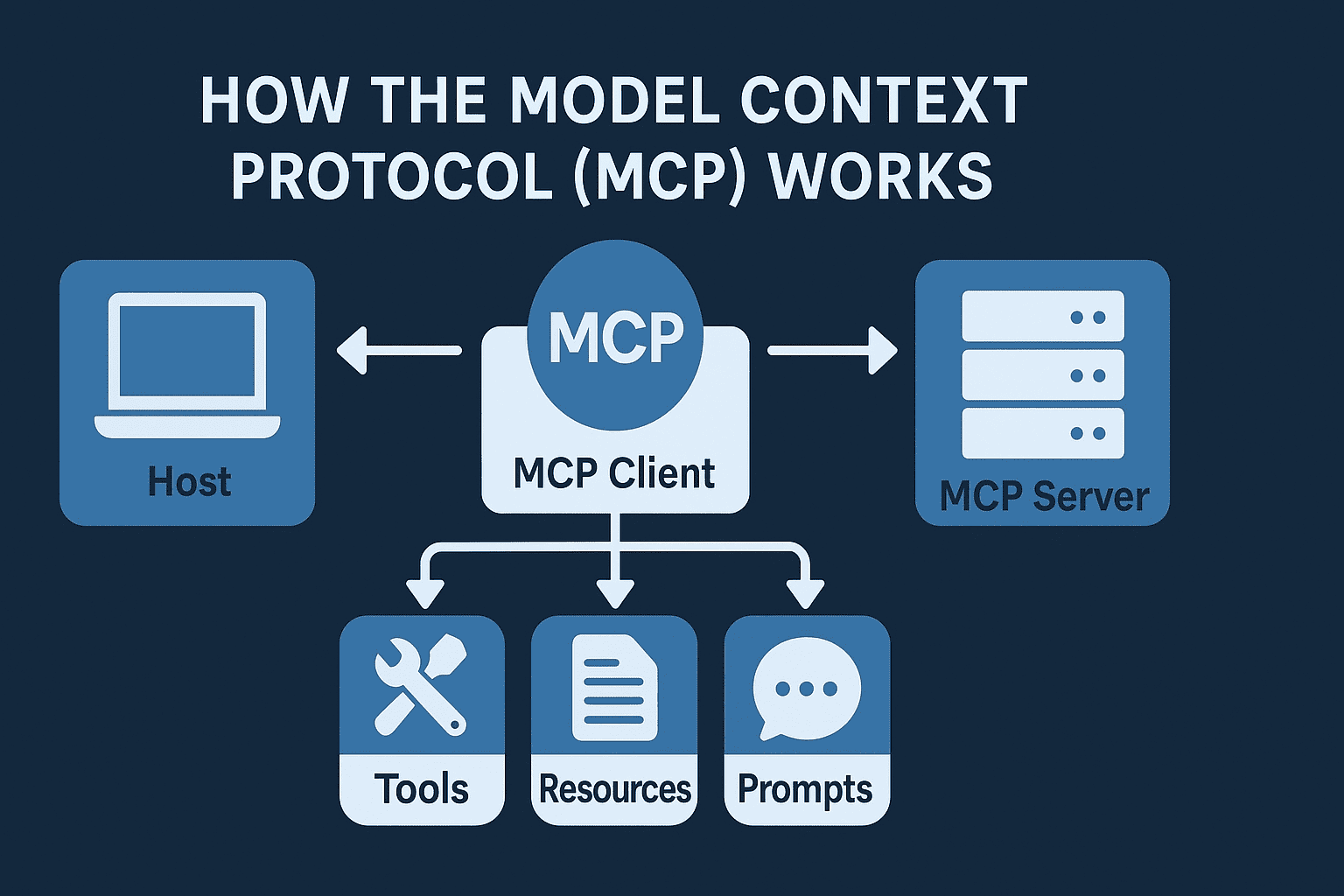
Core Participants
- Host: The container or orchestration layer that runs the AI application (client) and manages one or more clients.
- Client: The entity on behalf of the host that establishes a one-to-one connection with a particular MCP server. The client negotiates capabilities, sends requests, receives responses, handles notifications.
- Server: The external system (toolset, database, API, etc.) that exposes its capabilities (tools, resources, prompts) via MCP. The server receives requests, executes actions, returns results.
Layers
MCP separates concerns into two layers:
- Data layer: The protocol itself — the shape of messages, the JSON RPC 2.0 format, lifecycle messages, primitive types (tools, resources, prompts).
- Transport layer: How the messages get from client to server (stdin/stdout for local, HTTP+SSE for remote). Authentication, connection establishment, framing, etc.
Transport mechanisms
- Stdio transport: For clients and servers running on the same machine or tightly coupled processes. Low‐latency, no network overhead.
- Streamable HTTP transport: For remote or distributed servers. Uses HTTP POST for requests, optional SSE (Server-Sent Events) for streaming responses, and standard HTTP auth (Bearer tokens, API keys, OAuth).
How MCP Works (Workflow & Lifecycle)
Let’s walk through a typical session from initialization to usage, showing how a client and server interact via MCP.
Step 1: Initialization (Connection & Capability Negotiation)
- The client opens transport (e.g., HTTP or stdio) to the server.
- The client sends an initialize request: includes protocolVersion, client capabilities, identity/context.
- The server replies with its own initializeResult listing its capabilities (what tools/resources/prompts it supports) and maybe any server metadata.
- After successful negotiation, the client may send a notifications/initialized notification to mark readiness.
Step 2: Discovery
Once connected & negotiated, the client typically queries the server:
- tools/list → what tools can I call?
- resources/list → what resources (data sources) are available?
- prompts/list → what reusable prompt templates exist? The client may then fetch metadata or details for selected items (tools/get, resources/get, etc.). This gives the client (and by extension the AI application) a catalogue of what is possible.
Step 3: Usage / Execution
With knowledge of capabilities, the client (or the AI application via it) can:
- Call a tool: tools/call with tool id + arguments. The server executes the tool (e.g., query DB, call an API) and returns result.
- Read a resource: resources/read returns data associated with a resource (e.g., file contents, database record).
- Use a prompt: Fetch a prompt template via prompts/get, fill it with variables, supply to LLM.
- Client primitives: The server may request the client to do something:
- sampling/complete → ask client to get model completion via the host LLM.
- elicitation/collect → ask client to gather user input.
- logging/log → the server logs a message to the client (user visibility or audit).
Step 4: Notifications & State Changes
Servers can send notifications for changes: e.g., tools/list_changed, resources/list_changed, which allows clients to stay updated without polling. This supports dynamic environments (tools or resources may appear/disappear).
Step 5: Termination
When done, the client may send a shutdown or the transport may be closed gracefully, releasing resources and terminating the session.
Core Primitives Explained
Understanding the primitives is crucial to designing MCP-ready systems.
Tools
- Represent executable capabilities exposed by the server (e.g., “search documents”, “send email”, “execute query”).
- Use tools/list to discover, tools/call to execute.
- Important to define schema for arguments & results to keep interactions safe and predictable.
- E.g., if a document search tool takes “query” string and returns a list of document IDs + snippets.
Resources
- Represent data sources or context that the AI may need to read (or sometimes enumerate). Examples: file systems, dataset tables, API results.
- Methods like resources/list, resources/read.
- Important to enforce access controls (what parts of the data the model can see).
Prompts
- Templates of pre-written or reusable text blobs (system instructions, few-shot examples, etc.) the client can fetch and use when interacting with LLMs.
- Methods: prompts/list, prompts/get.
Client primitives (server → client)
- Sampling: Server requests client to call the host LLM to generate text. This offloads the model call logic to the host rather than embedding model logic in server.
- Elicitation: Server asks client for structured user input (for example, clarification, confirmation).
- Logging: Server sends messages or logs back to client for user visibility, audit, or debug.
Example Scenario
Let’s illustrate with a simple example: Suppose you’re building an AI assistant that helps a user by accessing a company spreadsheet and sending a summary via email.
- The assistant (host) instantiates a client to communicate with a server which exposes spreadsheet (resource) and email send tool.
- Client initializes connection, discovers available tools (email/send) and resources (spreadsheets/company_data).
- The AI decides:
- It will read spreadsheets/company_data/request_2025 resource via resources/read.
- Then call tools/call with email/send tool, passing arguments (recipient, subject, body) which is generated after reading the spreadsheet.
- Optionally, before sending the email, the server uses elicitation/collect to ask the user: “Do you confirm sending this email to John?”
- After user confirms (via client), the tool executes, result returned. Log the action via logging/log.
- Session ends.
Throughout this, the AI doesn’t need custom code for each new data source—just talk MCP.
Implementation Considerations & Best Practices
If you’re building or integrating MCP, here are things to watch for:
- Version negotiation: Support the protocolVersion and gracefully handle mismatches.
- Capability flags: Both client and server declare what part of MCP they support; implement defensively.
- Schema definitions: Strongly type tool arguments and result payloads. Avoid large unstructured blobs.
- Authentication & authorization: Especially for remote transport (Streamable HTTP), use OAuth or bearer tokens. Ensure granular permissions for tools/resources.
- User consent & prompt clarity: When exposing powerful tools, require explicit user prompts and confirmation flows (especially in enterprise).
- Discoverability: Make tool and resource lists clear and dynamically update if capabilities change.
- Audit logs & observability: Track which tool/resource was used, by which client, when and with what arguments—to support auditing and governance.
- Security hardening: Be aware of security risks such as prompt injection, combined tool misuse (exfiltration of data), identity fragmentation.
- Scalability: If you host many clients/servers, consider multiplexing, efficient streaming, and rate limits.
- Isolation: Clients should not pit multiple servers’ contexts together unless explicitly allowed. Each client ↔ server session isolates context.
Benefits & Trade-Offs
Benefits
- Modular architecture → easier to plug in new data sources or tools.
- Interoperability across AI models, clients and servers.
- Clear boundaries between AI logic and system logic.
- Governance ready → audit, access control, capability listing.
- Scalable integration → avoid custom glue for every new pair of model + data source.
Trade-Offs / What to watch
- Initial setup complexity: Building a proper MCP server (tools/resources/prompts) takes thought.
- Security risk: Exposing tools/resources must be done carefully—mishandled privileges can expose sensitive data or enable unwanted actions.
- Performance: Remote transport introduces latency; streaming or local transport may be required for real-time use cases.
- Adoption curve: Not all legacy systems will instantly support MCP, so hybrid approaches may be needed.
- Overhead: For very simple integrations, the protocol overhead might feel heavier than a direct custom API.
Conclusion
The Model Context Protocol (MCP) is a significant leap for the AI ecosystem: it provides a unified, standard way for language models and AI agents to interact with the real world — tools, data, workflows — without each integration reinventing the wheel.
For teams building AI-powered applications or agents, adopting MCP means better modularity, more reuse, clearer boundaries, enhanced governance and a smoother path to scaling. But with great power comes responsibility: proper architecture, security, and UX around tools/resources are essential to realise the promise safely.
If you’re considering building an AI application that needs more than just model output — that needs to act, to fetch, to update, to integrate — then MCP should be on your architecture radar.


